Data Conversion¶
Generally speaking, we cannot use unstructured data such as texts directly when we use machine-learning software. Such data are converted to “feature vectors” by being process called feature extraction in advance to the tasks. We use key-value type as feature vector in which keys are strings and values are numeric values. Through this process, we can handle unstructured raw data such as natural language texts, pictures and voice in a unified way. The data-conversion engine in Jubatus enables us to customize this feature-extraction process flexibly only by creating an easy configuration file.
Data-conversion is executed in two steps. First, we sanitize data with filtering. This filtering includes removing HTML tags and symbols which we know are unnecessary. Next, we extract features from sanitized data by feature-extraction process.
We can expect a series of process works well by the easiest configuration in most cases. The followings is one of the easiest configuration. In this configuration, we use each word separated by spaces a feature for string data. For numeric data, we use the value itself a feature. It is probable that doing some tuning this configuration to obtain training model with high precision and desirable result.
{
"string_filter_types": {},
"string_filter_rules": [],
"num_filter_types": {},
"num_filter_rules": [],
"string_types": {},
"string_rules": [
{ "key": "*", "type": "space", "sample_weight": "bin", "global_weight": "bin" }
],
"num_types": {},
"num_rules": [
{ "key": "*", "type": "num" }
],
"binary_types": {},
"binary_rules": []
}
Datum¶
It is very simple key-value called “datum” that we can use as a data type in Jubatus. datum has three key-value’s. One is “string_values”, whose key and value are both string data. The second is “num_values”, whose key is string data as string_values is, but value is numeric data. The last is “binary_values”, whose key is string data as string_values is, but value is arbitrary binary data. We can store in string_values arbitrary text data such as name, text, profession etc. We can store in num_values arbitrary numeric data such as age, income, the number of access etc. as a floating value. And, we can store in binary_values arbitrary binary data such as multimedia data like images and sounds. The data-conversion module extracts features which are used in machine learning tasks from these three types of data. Each key-value is represented neither as a map type nor a dictionary type, but as a set of pairs of keys and values for efficiency. The following is an example of a datum.
(
[
("user/id", "ippy"),
("user/name", "Loren Ipsum"),
("message", "<H>Hello World</H>")
],
[
("user/age", 29.0),
("user/income", 100000.0)
],
[
("user/image", "xxxxxxxx")
]
)
Name of keys cannot contain “$” sign.
For example, a datum consists of std::vector<std::pair<std::string, std::string> > , std::vector<std::pair<std::string, double> > and std::vector<std::pair<std::string, std::string> > in C++.
std::pair<T,U> (resp. std::vector<T>) is to C++ what tuple (resp. vector) is to Python.
Flow of Data Conversion¶
The following is the overview of data conversion.
As datum consists of string data, numeric data and binary data, there are flows of processing for each type of data.
For string data, first “string_filter_rules” is applied and the filtered data are added to the datum. Then, features are extracted from string data with “string_rules”.
For numeric data, first “num_filter_rules” is applied and filtered data are added to the datum. Then, features are extracted from string data with “num_rules”.
For binary data, features are extracted from binary data with “binary_rules”.
As some filters and feature extractors requires arguments, these are available in “string_rules” and “num_rules” if we prepare them in “string_types” and “num_types”, respectively.
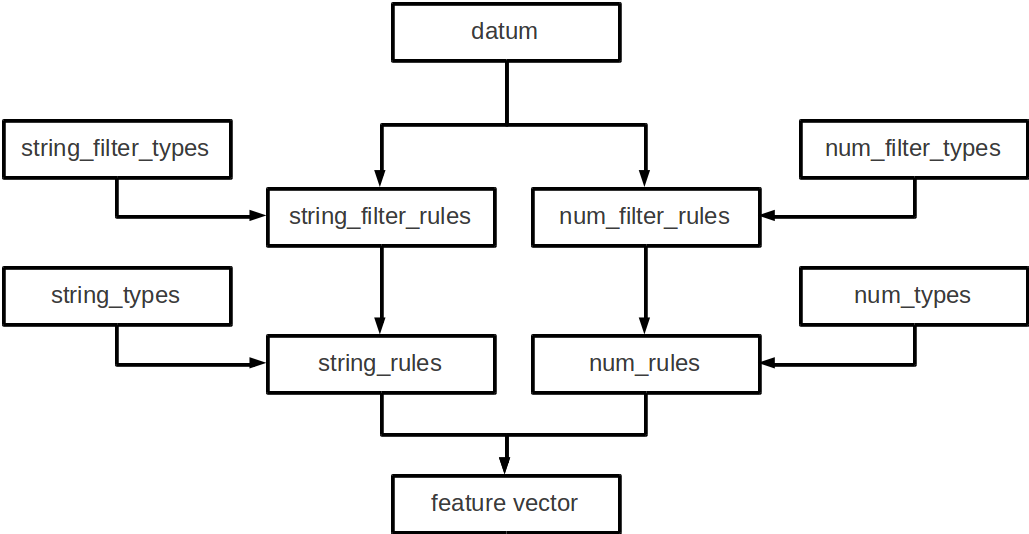
Figure : System of Conversion Engine
Filter¶
Jubatus has filtering system of raw data. This enables us to create additional key-value elements by converting existing key-value elements in a datum and to insert additional key-value elements by the filter. For example, let us suppose we have an original text as an HTML. Tags, such as <a>, in the data are in the way of training in many cases. Therefore, we want to filter and get rid of them in advance. In another example, we may remove quotes in e-mails (i.e. lines starts with “>”). We can make use of the filtering system in such cases.
As an example of usage, we remove HTML tags from strings whose key is “message”. We do it in two steps.
First, we define a rule which states “remove HTML tags”. Second, we apply this rule to data where key = "message".
This procedure is represented by the following configuration.
"string_filter_types": {
"detag": { "method": "regexp", "pattern": "<[^>]*>", "replace": "" }
},
"string_filter_rules": [
{ "key": "message", "type": "detag", "suffix": "-detagged" }
]
As a first step, we define a filter in “string_filter_types”. We name this filter “detag”. In “detag”, we define a filter which applies a method named “regexp”, which replaces “<[^>]*>” with “”. Next, we define to which elements in datum and how we apply this filter. We write it in “string_filter_rules”. The example above indicates that we apply the “detag” filter defined earlier to the value whose key is “message”, and that we store the resultant to “message-detagged” key, that is generated from the original key “message” and a suffix “-detagged”.
In another example, we can add one to “age” by the following configuration (in Japan, such a counting method is called “Kazoe Doshi”, or East Asian age reckoning).
"num_filter_types": {
"add_1": { "method": "add", "value": "1" }
},
"num_filter_rules": [
{ "key": "user/age", "type": "add_1", "suffix": "_kazoe" }
]
The procedure is the same as the previous example. A value in “user/age” added by one is stored in “usr/age_kazoe”.
By applying these two filters, we obtain the datum like this:
(
[
("user/id", "ippy"),
("user/name", "Loren Ipsum"),
("message", "<H>Hello World</H>"),
("message-detagged", "Hello World")
],
[
("user/age", 29.0),
("user/age_kazoe", 30.0),
("user/income", 100000.0)
]
)
These “types” and “rules” are optional. When you don’t specify these configurations, they are regarded as empty lists. Next section is devoted to more precise explanations of each filter.
string_filter_types¶
Specifies a dictionary that consists of <filter name>:<argument>. <filter name> is a string and <argument> is a dictionary whose keys and values are both strings. <argument> must contains a key named “method”. The rest of keys in <argument> are dependent on the value of “method”. The followings are available values of “method” and keys that must be specified.
-
regexp This filter converts substrings that a specified regular expression matches to a specified string.
pattern: Specifies a regular expression to match. replace: Specifies a string to replace with. For list of regular expressions available, refer to the documentation of the regular expression engine (oniguruma or re2). The regular expression engine can be selected at compile time (oniguruma is used when using binary packages).
For example, in order to remove all HTML tags, we should define such a string_filter_type.
"string_filter_types": { "detag": { "method": "regexp", "pattern": "<[^>]*>", "replace": "" } }
-
dynamic Use a plugin. See below for further detail.
path: Specifies a path to the plugin. function: Specifies a function to be called in a plugin. It depends on the plugin.
string_filter_rules¶
Specifies rules how to apply filters. The rules are checked in order. If a datum is matched to a rule, the corresponding filter is applied and a converted value is stored to the datum. Application is called recursively, that is, rest of filters is applied to the original values and the converted values. Each rule is represented as a dictionary whose keys are “key”, “except” (optional), “type” and “suffix”.
key: Specifies to which keys in a datum we apply the rule. We describe it in datail later. except: Specifies which keys to exclude from the match. This is an optional parameter. We describe it in datail later. type: Specifies the name of the filter used. This filter must be defined in “string_filter_types”. No filters are available by default. suffix: Specifies a suffix of a key where the result of filtering is stored. For example, if “suffix” is “-detagged” and a filter is applied to “name” key in a datum, the result is stored in “name-detagged” key.
“key” and “except” can be specified in one of the following formats. For each key in a datum, all rules checked to be applicable. It means that if a single key matches n rules, every corresponding filter will be applied to the original key. Then, new n keys are added to the datum. Every “key” and “except” in this document is in the same format. Similarly, it happens that multiple rules are applied to a single key.
Value Meaning “*” or “” Matches all keys in a datum. That is, this rule is applied to every keys in the datum. “XXX*” Matches keys whose prefixes are “XXX”. “*XXX” Matches keys whose suffixes are “XXX”. “/XXX/” “XXX” is interpreted as a regular expression. Matches keys that the expression matches. otherwise If the key is none of the above, it matches to keys that are identical to the given string.
When “except” is specified and both “key” and “except” matched, the rule will be skipped. For example, by using {“key”: “*”, “except”: “foo”, … }, you can define the rule which will be applied for every keys other than “foo”.
num_filter_types¶
Specifies a dictionary consists of <filter name>:<argument>, same as “string_filter_types”. We can use it almost in the same way as “string_filter_types”. <filter name> is a string and <argument> is a dictionary whose keys and values are both strings. <argument> must contains a key named “method”. The rest of keys in <argument> are dependent on the value of “method”. The followings are available values of “method” and keys that must be specified.
-
add Add specified value to the original value.
value: Specifies value to add. For example, if we add 3 to the original value, we use “3”. Note that it is not numeric but a string. It is treated as a doubled precision floating-point number internally.
-
linear_normalization It normalizes the input value linearly between 0 to 1. It requires two arguments “min” and “max”, and these values cannot be omitted. It transforms given value x to be between 0 to 1 with formula (x-min) / (max - min). If the x is smaller than “min”, it is truncated to 0. If the x is bigger than “max”, it is truncated to 1. These truncation behavior is switched by “truncate” option. If “min” is greater than “max”, the invalid_parameter exception will be raised and fail to create converter.
min: Input minimum value to be input. If the minimum value is 0, you have to input as “0”. Notice that it is not numeric but string type. It is treated as a floating-point number internally. You cannot omit this argument. max: Input maximum value to be input. If the maximum value is 100, you have to input as “100”. Notice that it is not numeric type but string type. It is used as a double precision double type inside. You cannot omit this argument. truncate: Behavior of truncating value which is less than “min” or more than “max”. In case it is “True”, values less than “min” will become 0 and more than “max” will become 1. You can omit this parameter. In case you omit, this parameter is to be “True” automatically. An example of using this function is below.
"num_filter_types" : {
"zero_to_hundred": { "method": "linear_normalization", "min": "0", "max":"100" }
},
"num_filter_rules" : [
{"key" : "*", "type": "zero_to_hundred", "suffix": "linear_normalized" }
],
-
gaussian_normalization It normalizes values between -1 to +1, supposing values are distributed on normal distribution. It requires two arguments “average” and “standard_deviation”, and these values cannot be omitted. It transforms given value x to be -1 to +1 with formula (x - average) / standard_deviation. For this reason, anomaly value can be less than -1 or more than +1. You cannot specify negative value for “standard_deviation”. It causes invalid_parameter exception.
average: Give average of input data. If average value is 80, you should specify like “80”. Notice that it is not numeric but string type. Value is treated as doubled precision floating point value inside. standard_deviation: Give standard deviation of input data. If standard deviation value is 2.3, you should specify like “2.3”. Notice that it is not numeric but string type. Value is treated as doubled precision floating point value inside. An example of using this function is below.
"num_filter_types" : {
"gaussian_80_2.3": { "method": "gaussian_normalization", "average": "80", "standard_deviation":"2.3" }
},
"num_filter_rules" : [
{"key" : "*", "type": "gaussian_80_2.3", "suffix": "gaussian_normalized" }
],
-
sigmoid_normalization It normalizes values between 0 to 1, by using sigmoid function. It requires two parameters “gain” and “bias”. In case you omitted these values, these values will be “1.0” and “0.0” respectively. It transforms given value x to be 0 to 1 with formula 1 / 1 + e ^ (-gain * (x - bias)).
gain: Specify the gainof sigmoid function. The more big value specified, sigmoid function will be more steep. Ifgainvalue is 0.5, you should specify like “0.5”. Notice that it is not numeric but string type. Value is treated as doubled precision floating point value inside. In case you omit this parameter, “1.0” is used.bias: Specify the biasof sigmoid function. if Ifbiasvalue is 3, you should specify like “3”. Notice that it is not numeric but string type. Value is treated as doubled precision floating point value inside. In case you omit this parameter, “0.0” is used.An example of using this function is below.
"num_filter_types" : {
"sigmoid": { "method": "sigmoid_normalization", "gain": "0.05", "bias":"5" }
},
"num_filter_rules" : [
{"key" : "*", "type": "sigmoid", "suffix": "sigmoid_normalized" }
],
-
dynamic Use a plugin. See below for further detail.
path: Specifies a full path of a plugin. function: Specifies a function to be called in the plugin.
num_filter_rules¶
Like “string_filter_rules”, it specifies rules how to apply filters. Each rule is a dictionary whose keys are “key”, “except” (optional), “type” and “suffix”.
key: Specifies to which keys in a datum we apply the rule. For further explanation, please read counterpart in “string_filter_rules” section. except: Specifies which keys to exclude from the match. This is an optional parameter. For further explanation, please read counterpart in “string_filter_rules” section. type: Specifies a name of a filter used. This filter must be defined in “string_filter_types”. No filter is available if no filter is defined in “string_filter_types”. suffix: Specifies a suffix of a key where the result of a filtering is stored. For example, if “suffix” is “-detagged” and a filter is applied to “name” key in a datum, the result is stored in “name-detagged” key.
Format of “key” and “except” is written in “string_filter_rules” section.
Feature Extraction from Strings¶
In this section, we explain mechanism of the feature extraction from strings. We also explain how to apply these extraction rules. The following is an example of a configuration. In this configuration, we use as features “user/name” itself, every 2-grams of “message”, and every word in “message-detagged” separated by spaces.
"string_types": {
"bigram": { "method": "ngram", "char_num": "2" }
},
"string_rules": [
{ "key": "user/name", "type": "str", "sample_weight": "bin", "global_weight": "bin" },
{ "key": "message", "type": "bigram", "sample_weight": "tf", "global_weight": "bin" },
{ "key": "message-detagged", "type": "space", "sample_weight": "bin", "global_weight": "bin" }
]
string_types¶
Feature extractors of strings are defined in “string_types”. Some feature extractors must be defined in “string_types”. An exapmle of such extractors is one which requires arguments such as path. As “string_filter_types”, it specifies a dictionary which consists of <extractor name>:<argument>. Name of extractors cannot contain “@” sign. <argument> is a dictionary whose key and value are both strings and it must contain a key named “method”. The rest of the keys in <argument> are dependent on the value of “method”. The followings are available values of “method” and keys that must be specified.
-
ngram Use contiguous N characters as a feature. Such a feature is called an N-gram feature.
char_num: Specifies N or length of substring. N must be a positive integer. “char_num” must be specified with string type (e.g. “2”), not numeric type (e.g. 2). The following configuration specifies bigram (2-gram) and trigram (3-gram).
"string_types": { "bigram": { "method": "ngram", "char_num": "2" }, "trigram": { "method": "ngram", "char_num": "3" } }
-
regexp Extract keywords from given document by way of regular expression matching with and use each keyword as a feature. Matching is executed continuously, that is, every match is used as a feature.
pattern: Specifies mathing pattrn. group: Specifies group to be extracted as a keyword. If this value is 0, whole match is used as a keyword. If value is positive integer, only specified group extracted with () is used. Default value is 0. “group” must be specified with string type (e.g. “2”), not numeric type (e.g. 2). For list of regular expressions available, refer to the documentation of the regular expression engine (oniguruma or re2). The regular expression engine can be selected at compile time (oniguruma is used when using binary packages).
The following is simplest example in which we extract every representation of date (YYYY/MM/DD).
"string_types": { "date": { "method": "regexp", "function": "create", "pattern": "[0-9]{4}/[0-9]{2}/[0-9]{2}" } }
If we use only a part of the matches, we make use of “group” argument. For example, representation of age may be extracted with such a configuration.
"string_types": { "age": { "method": "regexp", "pattern": "(age|Age)([ :=])([0-9]+)", "group": "3" } }
-
split Separate given string by specified characters and use a set of substrings as features.
separators: Specifies characters to separate the string. If multiple characters are set, each of them are used as a separator. The followings are examples of configuration to split strings with comma “,” and 3 characters {“a”, “b”, “c”}.
"string_types": { "comma_split": { "method": "split", "separators": "," }, "abc_split": { "method": "split", "separators": "abc" } }
-
dynamic Use a plugin. See below for further detail.
path: Specifies a path to a plugin. function: Specifies a function to be called in a plugin.
string_rules¶
Specifies how to extract string features. As “string_filter_rules”, it consists of multiple rules. Each rule is a dictionary whose keys are “key”, “except” (optional), “type”, “sample_weight” and “global_weight”. These rules specifies how we extract rules from given strings and their weights used in calculating scores. A weight is calculated with two parameters, “sample_weight” and “global_weight”. In concrete, the weight is the product of these two weights.
key: Specifies to which keys in a datum we apply the rule. For further explanation, please read counterpart in “string_filter_rules” section.
except: Specifies which keys to exclude from the match. This is an optional parameter. For further explanation, please read counterpart in “string_filter_rules” section.
type: Specifies the name of an extractor in use. The extractor is either one defined in “string_types” or one of pre-defined extractors. The followings are the pre-defined extractors.
Value Meaning "str"Use given string itself as a feature without separating it. "space"Separate given string by spaces and use a set of substrings as features. sample_weight: Specifies weight of each feature. Note that as term frequency is, “sample_weight” is uniquely defined if feature and datum are specified.
Value Meaning "bin"sample_weight is 1 for all features and all data. "tf"sample_weight is frequency of the feature in given string. It is called Term Frequency. For example, if “hello” is appeared five times, its sample_weight for this string is 5. "log_tf"sample_weight is the logarithm of tf added by 1. For example, if “hello” is appeared five times, its sample_weight is log(5+1). global_weight: Specifies global weight calculated from data inputted so far.
Value Meaning "bin"global_weight is 1 for all features. "idf"global_weight is the inverse of logarithm of normalized document frequency. It is called Inverse Document Frequency. For example, if a feature is included in 50 documents of all 1000 documents, its global_weight is log(1000/50). Roughly speaking, the less a feature frequently appears, the greater its idf is. "idf1"global_weight is calculated by "idf"value + 1.0. See the description under the table for details."bm25"global_weight is calculated by Okapi BM25 method. In addition to the feature frequency, BM25 uses the length of the document that the feature appears. Roughly speaking, the less feature frequently appears and the short the length of the document the feature is in, the greater its weight is. Generally used in combination with "sample_weight": "tf". It is empirically known that BM25 weighting is better than IDF. Note that calculation cost is higher than IDF.
In most of machine learning tasks, it works well even if we use “bin” in both sample_weight and global_weight. In some kind of tasks, in which weight itself is trained, weight are adjusted automatically even if we set “bin” in sample_weight and global_weight. Classification is an example of such a task.
By using "idf1" instead of "idf" in global_weight, you can workaroud the problem that features in the first document or features that appear in all documents are not added to the model.
When "idf" is used, IDF value of features of the first document (e.g., the first record registered to Recommender) or features that appear in all documents (e.g., a feature "the" appear in 1,000 out of 1,000 documents) become 0; this makes the weight of the feature to become 0, causing the feature not be trained to the model.
"idf1" uses IDF value + 1.0 as a weight value to train features in such situations.
Feature Extraction from Numbers¶
As with strings, feature extraction rules are also described for numeric types. We can make user-defined extractors for numeric types, too.
"num_types": {
},
"num_rules": [
{ "key": "user/age", "type": "num" },
{ "key": "user/income", "type": "log" },
{ "key": "user/age_kazoe", "type": "num" }
]
num_types¶
Feature extractors for numeric data are defined in “num_types”. As with “string_types”, it specifies a dictionary which consists of <extractor name>:<argument>. <argument> is a dictionary whose keys and values are both strings and must contain a key named “method”. The rest of keys in <argument> are dependent on the value of “method”. The followings are available values of “method” and keys that must be specified.
-
dynamic Use a plugin. See below for further detail.
path: Specifies a path to a plugin. function: Specifies a function to be called in a plugin.
num_rules¶
Specifies how to extract numeric features. As “string_rules”, it consists of multiple rules. Each rule is a dictionary whose keys are “key”, “except” (optional) and “type”. It depends on “type” how to specify weight and name features.
key: Specifies to which keys in a datum we apply the rule. For further explanation, please read counterpart in “string_filter_rules” section.
except: Specifies which keys to exclude from the match. This is an optional parameter. For further explanation, please read counterpart in “string_filter_rules” section.
type: Specifies the name of extractor in use. The extractor is either one defined in “num_types” or one of pre-defined extractors. The followings are the pre-defined extractors.
Value Meaning "num"Use given number itself as weight. "log"Use natural logarithm of given number as weight. If the number is not positive, weight is 0. "str"Use given number as a string. This extractor is used when the value of the number is not important, such as user ID. Weight is set to be 1.
Feature Extraction from Binary Data¶
As with strings, feature extraction rules are also described for binary types. We can make user-defined extractors for binary types, too.
binary_types¶
Feature extractors for binary data are defined in “binary_types”. As with “string_types”, it specifies a dictionary which consists of <extractor name>:<argument>. <argument> is a dictionary whose keys and values are both strings and must contain a key named “method”. The rest of keys in <argument> are dependent on the value of “method”. The followings are available values of “method” and keys that must be specified.
-
dynamic Use a plugin. See below for further detail.
path: Specifies a path to a plugin. function: Specifies a function to be called in a plugin.
binary_rules¶
Specifies how to extract binary features. As “string_rules”, it consists of multiple rules. Each rule is a dictionary whose keys are “key”, “except” (optional) and “type”. It depends on “type” how to specify weight and name features.
key: Specifies to which keys in a datum we apply the rule. For further explanation, please read counterpart in “string_filter_rules” section. except: Specifies which keys to exclude from the match. This is an optional parameter. For further explanation, please read counterpart in “string_filter_rules” section. type: Specifies the name of extractor in use. The extractor is either one defined in “binary_types”. Note that no pre-defined extractors are prepared.
Feature Extraction from Combination Data¶
We can make new combination features by combining number features or string features. As with strings and numbers, feature extraction rules are also described for combination types. We can make user-defined extractors for combination types, too.
We show a sample configuration. We can make new features by summing up (‘add’) or multiplying (‘mul’) two numeric features or string features.
In this configuration, we can combinate string features that are converted by “bin/bin” method, i.e. sample_weight and global weight are “bin”. If you want to combinate all string features, you needs to write keys like “*@str*”.
"num_types": {},
"num_rules": [
{"key": "*", "type": "num"}
],
"string_types": {},
"string_rules": [
{"key": "*": "type": "str", "sample_weight": "bin", "global_weight": "bin"},
],
"combination_types": {},
"combination_rules": [
{ "key_left": "*@num", "key_right": "*@num", "type": "add"},
{ "key_left": "*@num", "key_right": "*@num", "type": "mul"},
{ "key_left": "*@str#bin/bin", "key_right": "*@str#bin/bin", "type": "add"}
{ "key_left": "*@str#bin/bin", "key_right": "*@str#bin/bin", "type": "mul"}
]
combination_types¶
Feature extractors for combination data are defined in “combination_types”. As with “string_types”, it specifies a dictionary which consists of <extractor name>:<argument>. <argument> is a dictionary whose keys and values are both strings and must contain a key named “method”. The rest of keys in <argument> are dependent on the value of “method”. The followings are available values of “method” and keys that must be specified.
-
dynamic Use a plugin. See below for further detail.
path: Specifies a path to a plugin. function: Specifies a function to be called in a plugin.
combination_rules¶
Specifies how to extract combination features. As “string_rules”, it consists of multiple rules. Each rule is a dictionary whose keys are “key_left”, “key_right”, “except_left” (optional), “except_right” (optional) and “type”. It depends on “type” how to specify weight and name features.
key_left: The first argument. It specifies to which keys in a datum we apply the rule. For further explanation, please read counterpart in “string_filter_rules” section.
key_right: The second argument. Same as above.
except_left: The exception key for “key_left”. It specifies which keys to exclude from the match. This is an optional parameter. For further explanation, please read counterpart in “string_filter_rules” section.
except_right: The exception key for “key_right”. Same as above.
type: It specifies the name of extractor in use. The extractor is either one defined in “combination_types” or one of pre-defined extractors. The followings are the pre-defined extractors.
Value Meaning "add"Use sum of given values as weight. "mul"Use product of given values as weight.
Hashing Key of Feature Vector¶
To reduce memory consumption, Jubatus can hash keys of feature vectors. By hashing feature vector keys, you can limit a maximum dimension of feature vectors, although this may decrease the accuracy of the result when one hash value collides with another.
This function is disabled by default.
To use this option, specify the hash_max_size in the converter configuration. It must be a positive integer.
{
"string_filter_types": {},
"string_filter_rules": [],
"num_filter_types": {},
"num_filter_rules": [],
"string_types": {},
"string_rules": [{"key": "*", "type" : "str", "sample_weight": "bin", "global_weight" : "bin"}],
"num_types": {},
"num_rules": [{"key" : "*", "type" : "num"}],
"binary_types": {},
"binary_rules": [],
"hash_max_size": 16
}
The appropriate number of hash_max_size depends on the data set you use and your environment.
Note that hash_max_size is not a limit for a number of keys in the original datum, but a number of keys in (converted) feature vectors.
Plugins¶
We can use plugins of filters and extractors in fv_converter. A plugin is a single dynamic library file (.so file). We will explain how to make plugins later. In this section, we will describe how to use plugins.
How to specify plugin is same in both filters and extractors.
In CLASS_types (CLASS is either string or num), we should specify “dynamic” in “method”, a path to a .so file in “path” and the name of function defined in the plugin in “function”.
We have two methods to specify a plugin path.
When the path contains ‘/’ character, it is regarded as a relative or absolute path.
In this case, Jubatus try to load it from the relative path from the current path, or the absolute path.
When the path doesn’t contain ‘/’ character, Jubatus try to load it from two load path:
- A directory specified with an environment variable
JUBATUS_PLUGIN_PATH. - The default plugin directory set in build step (
$PREFIX/lib/jubatus/pluginor$PREFIX/lib64/jubatus/pluginin most cases).
Argument of the function is specified by other parameters.
In Jubatus, we can extract features from strings using two pre-defined plugins. We can also extract features from images using a pre-defined plugin. Note that some plugins are not available depending on your compile options.
Feature Extraction from Strings¶
We can use MeCab pluigin and ux plugin in jubatus.
-
libmecab_splitter.so We can specify this plugin in “string_types”. Separate given Japanese document into words by MeCab and use each word as a feature. This plugin is available only when compiled with
--enable-mecab. This plugin is available in binary package.function: Specify “create”. arg: Specify arguments to MeCab engine (in the following example, we use -d to specify the dictionary directory). “arg” is not specified, Mecab works with default configuration. Refer to the document of MeCab about how to specify arguments. ngram: Specify N of morpheme (word) N-gram that is constructed from morphemes extracted by MeCab. When “ngram” is not specified, N is assumed as 1, i.e., do not construct morpheme N-gram and just use each morphemes as a feature. Note that N must be specified as string, not integer (see the example below.) base: Specify whether to use the base form of morphemes. Specify “true” to use the base form, or “false” to use the surface. Even when “true” is specified, the surface is used for morphemes that does not have the base form (e.g., proper nouns.) When “base” is not specified, “false” is assumed. Note that “true” or “false” must be specified as string (see the example below.) include_features: Specify pattern of part-of-speech to use. Patterns are expected to match with the CSV representation of MeCab output (e.g., 名詞,固有名詞,組織,*,*,*,*.) The format is the same as inkeyofstring_filter_rules. For example, to extract nouns only, specify"名詞,*". To specify multiple patterns, join the patterns with | (e.g.,"名詞,*|動詞,*".) When “include_features” is not specified, “*” is assumed, i.e., all morphemes are used.exclude_features: Specify pattern of part-of-speech to exclude. The format is the same as include_features. When bothinclude_featuresandexclude_featuresare specified, morphemes that matches withinclude_featuresand does not match withexclude_featuresare extracted. When “exclude_features” is not specified, “” is assumed, i.e., nothing is excluded."string_types": { "mecab": { "method": "dynamic", "path": "libmecab_splitter.so", "function": "create", "arg": "-d /usr/lib64/mecab/dic/ipadic", "ngram": "1", "base": "false", "include_features": "*", "exclude_features": "" } }
-
libux_splitter.so We can specify this plugin in “string_types”. Extract keywords from given document by way of dictionary matching with ux-trie and use each keyword as a feature. Matching is a simple longest matching. Note that it is fast but precision may be low. This plugin is available only when compiled with
--enable-ux. This plugin is available in binary package.function: Specifies “create”. dict_path: Specifies a full path of a dictionary file. The dictionary file is a text file that consists of keywords, one keyword per one line. "string_types": { "ux": { "method": "dynamic", "path": "libux_splitter.so", "function": "create", "dict_path": "/path/to/keyword/dic.txt" } }
Feature Extraction from Images¶
We can use OpenCV in jubatus.
-
libimage_feature.so We can specify this plugin in “binary_types”. It extracts features from given images by OpenCV . This plugin is available only when compiled with
--enable-opencv. This plugin is available in binary package.function: Specifies “create”.
algorithm: Specifies the feature extraction algorithm. In jubatus, we can use RGB or ORB to extact featrures from images. It should be noted that in both algorithm, we detect keypoints by Dense Sampling (which extracts features from all pixels of the image.)
Value Meaning "RGB"Extracts RGB values in each pixel. "ORB"Makes binary strings by using intensity of pixels. We can refer OpenCV documentation in detail. resize: Specifies whether to resize the image. Specify “true” to resize image, or “false” not to resize it. When
resizeis not specified, “false” is assumed.x_size: Specifies the length of resized images. We can specify it when
resizeis “true”.y_size: Specifies the height of resized images. We can specify it when
resizeis “true”."binary_types": { "image": { "method": "dynamic", "path": "libimage_feature.so", "algorithm":"ORB", "resize":"true" "x_size":"120.0" "y_size":"120.0" "function": "create", } }
Python Bridge¶
Using Python Bridge, you can write your own feature extraction types in Python. The following bridge interfaces are available.
Interface Usage string_featureFeature extraction for string values. ( string_types)word_splitterFeature extraction (split from input text only) for string values. ( string_types)num_featureFeature extraction for number values. ( num_types)binary_featureFeature extraction for binary values. ( binary_types)
Configuration¶
The Python Bridge is provided as a plugin.
-
libpython_bridge.so You can specify this plugin in
string_types,num_typesorbinary_types. This plugin is available only when compiled with--enable-python-pluginor--enable-python3-plugin. This plugin is available in binary package (except for RHEL 6).function: Specify the interface name described above (e.g., string_feature).module: Specifies a Python module. class: Specifies a Python class in the module. "num_types": { "multiply_by_3": { "method": "dynamic", "path": "libpython_bridge.so", "function": "num_feature", "module": "number_multiplier", "class": "NumberMultiplier", "n": "3" } }
In addition, you can specify other parameters to be passed to the Python class. Note that both keys and values of parameters must be string.
Common Requirements for Python Module¶
To implement a feature extraction type in Python, you need to define a Python class in a module, instead of writing plugin in C++. Here is an example.
class MyFeatureExtractor(object):
@classmethod
def create(cls, param):
return cls()
def extract(self, key, value):
return [(u'key1', 1.0), (u'key2', 2.0)]
Requirements for the Python class is as follows:
- The class must implement
createclass method. The argumentparamis a dict object of configuration parameters. - The class must implement an instance method with signature required for each interface. See sections below for details.
- The module containing the class must be in any of
sys.path, any of paths defined inPYTHONPATHenvironment variable, or the default Python plugin module directory ($PREFIX/lib/jubatus/python). Note that the Python Bridge plugin installed via binary package does not recognizepyenv. To use packages installed viapyenv, usePYTHONPATHbefore starting Jubatus process (e.g.,export PYTHONPATH="$HOME/.pyenv/versions/3.5.1/lib/python3.5/site-packages").
Errors of Python codes are reported to the standard error.
In the following sections, we use Python 3.x type names.
If you are using Python 2.x, str and bytes types should read unicode and str types, respectively.
string_feature Interface¶
Instance method named extract that takes 1 argument is required for the class.
The arguments is a input text (
strtype).The return value must be a list of 4 element tuples. Each element represents:
- beginning position of the extracted part (
inttype); can be0. - length of the part (
inttype); can be0. - extracted string for the part (
strtype) - score for the part (
doubletype); generally use1.0.
- beginning position of the extracted part (
def extract(self, text):
return [(0, 0, text, 1.0)]
The example implementation to apply stemming (Porter Stemmer) for English sentence is available by default.
See the source of sentence_stemmer module for details.
You need to install Natural Language Toolkit for this example to work (pip install nltk).
"string_types": {
"stem_sentence": {
"method": "dynamic",
"path": "libpython_bridge.so",
"function": "string_feature",
"module": "sentence_stemmer",
"class": "SentenceStemmer"
}
},
"string_rules": [
{ "key": "*", "type": "stem_sentence", "sample_weight": "tf", "global_weight": "bin" }
]
word_splitter Interface¶
Instance method named split that takes 1 argument is required for the class.
The arguments is a input text (
strtype).The return value must be a list of 2 element tuples. Each element represents:
- beginning position of the extracted part (
inttype). - length of the part (
inttype).
- beginning position of the extracted part (
def split(self, text):
return [(0, 1)]
The example implementation to split the text with space is available by default. See the source of space_splitter module for details.
"string_types": {
"split_by_space": {
"method": "dynamic",
"path": "libpython_bridge.so",
"function": "word_splitter",
"module": "space_splitter",
"class": "SpaceSplitter"
}
},
"string_rules": [
{ "key": "*", "type": "split_by_space", "sample_weight": "tf", "global_weight": "bin" }
]
num_feature Interface¶
Instance method named extract that takes 2 arguments is required for the class.
The arguments are datum key name (
strtype) and its value (doubletype).The return value must be a list of 2 element tuples. Each element represents:
- name of the feature key (
strtype). - value for the key (
doubletype).
- name of the feature key (
def extract(self, key, value):
return [(key, value)]
The example implementation to apply multiplication for numbers is available by default. See the source of number_multiplier module for details.
"num_types": {
"multiply_by_3": {
"method": "dynamic",
"path": "libpython_bridge.so",
"function": "num_feature",
"module": "number_multiplier",
"class": "NumberMultiplier",
"n": "3"
}
},
"num_rules": [
{ "key": "*", "type": "multiply_by_3" }
]
binary_feature Interface¶
Instance method named extract that takes 2 arguments is required for the class.
The arguments are datum key name (
strtype) and its value (bytestype).The return value must be a list of 2 element tuples. Each element represents:
- name of the feature key (
strtype). - value for the key (
doubletype).
- name of the feature key (
def extract(self, key, value):
return [(key, len(value))]
The example implementation to extract length of the binary data is available by default. See the source of binary_length module for details.
"binary_types": {
"extract_length": {
"method": "dynamic",
"path": "libpython_bridge.so",
"function": "binary_feature",
"module": "binary_length",
"class": "BinaryLengthExtractor"
}
},
"binary_rules": [
{ "key": "*", "type": "extract_length" }
]