Architecture¶
Here is a brief architecture of Jubakit:
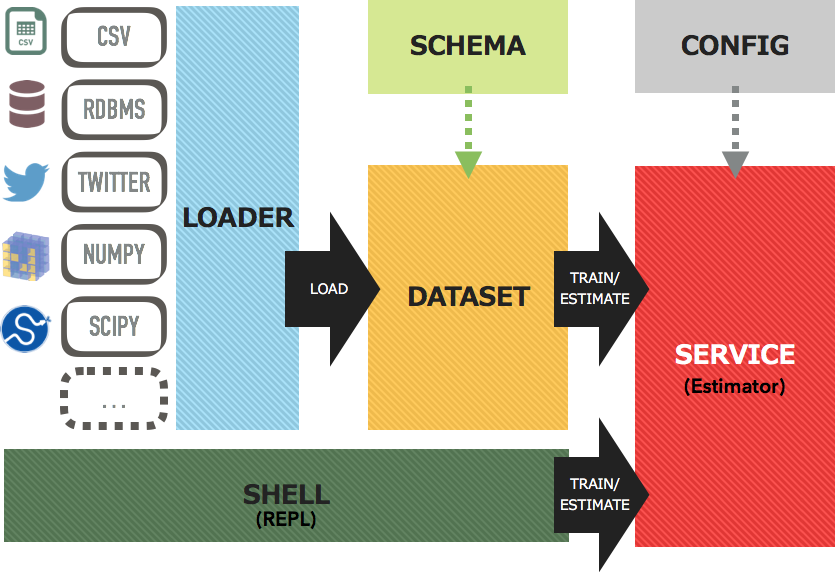
There are 6 components that consists of Jubakit:
- Loader fetches data from various data sources (e.g., CSV file, RDBMS, MQ, Twitter stream, etc.) in key-value format.
- Schema defines the data type (string feature, numeric feature, ground truth (label), etc.) for each keys of data loaded by Loader.
- Dataset transforms records loaded from Loader into Jubatus Datum using Schema. Dataset is an abstract representation of a sequence of data.
- Service makes update/analyze RPC calls to Jubatus servers for each record in Dataset and returns the result.
- Config defines parameters of Service.
- Shell provides an interactive command line interface to communicate with Jubatus servers.
Note that Schema, Dataset and Config are defined for each Service.
For example, you must use jubakit.classifier.Schema for jubakit.classifier.Classifier service, not jubakit.anomaly.Schema.