データ変換¶
一般的に機械学習処理を行う場合、テキストなどの生の非定形データ(例えば HTML や Twitter のつぶやき情報など)を直接扱うことはできない。 こうしたデータは事前に特徴抽出というステップを経て、一般に特徴ベクトルと呼ばれる形式に変換される。 Jubatus における特徴ベクトルの中身は、文字列をキー、数値型を値とする key-value 型である。 この変換を行うことで、自然言語のデータ、画像データ、音声データなどの非定型の生データを統一的に扱うことができる。
Jubatus の特徴ベクトル変換器は、この特徴抽出処理を簡単な設定ファイルを書くことで柔軟にカスタマイズすることを可能にする。
概要¶
データ変換は「フィルター」と「特徴抽出」の 2 段階で行われる。
まず、フィルター処理によって、データを整形する。 この処理は、例えばHTMLテキストのタグを除去したり、学習にとって不要であることが予めわかっている記号列などを取り除く。 その次に、特徴抽出処理によって、フィルターされたデータから特徴を抽出する。
例えば、フィルタリングの結果として、「世の中ではビッグデータというキーワードが注目されているが、一口にビッグデータといっても立場や観点によって定義は様々です」という文字列が与えられたとする。 ここからキーワードを抽出すると、「ビッグデータ」、「世の中」、「キーワード」、「定義」といった特徴が得られる。 これらの特徴を出現頻度で重み付けをする(出現回数をカウントする)と、「ビッグデータ:2」、「世の中:1」、「キーワード:1」、「定義:1」という結果が得られる。 この一連の流れの中で、与えられた文字列から特徴を抽出し、出現頻度等によって重み付けをするまでの処理を特徴抽出という。
Jubatus では、「フィルタリングでデータからどのような要素を取り除くか」、「特徴抽出でどのように特徴の抽出を行い、どのように重み付けをするか」を、JSON形式の設定ファイルで定義することができる。 一連の処理は、最もシンプルな設定によって多くの場合はうまく動くことが予想される。 以下に最もシンプルな設定を記載する。 この設定を利用すると、文字列データは全てスペース文字で分割してそれぞれの単語を特徴量とし、数値データはその値をそれぞれ特徴量として利用する。 実際にアプリケーションを書くときに、より高い精度の学習結果を求める場合は、設定をチューニングすることで望ましい結果を得られる可能性がある。
{
"string_filter_types": {},
"string_filter_rules": [],
"num_filter_types": {},
"num_filter_rules": [],
"string_types": {},
"string_rules": [
{ "key": "*", "type": "space", "sample_weight": "bin", "global_weight": "bin" }
],
"num_types": {},
"num_rules": [
{ "key": "*", "type": "num" }
],
"binary_types": {},
"binary_rules": []
}
Datum¶
Jubatusで利用できるデータ形式は、datumと呼ばれる非常にシンプルなkey-valueデータ形式である。 datumには3つのkey-valueが存在する。 一つはキーも値も文字列の文字列データ (string_values) である。 2つ目は、キーは同様に文字列だが、値は数値の数値データ (num_values) である。 最後が、キーは同様に文字列で、値が任意のバイナリデータ(binary_values)である。 string_values には名前、テキスト、職業など、任意のテキストデータを入れることができる。 num_values には年齢、年収、アクセス回数など、任意の数値データを浮動小数点型として入れることができる。 binary_values には画像や音声などのマルチメディアデータなど、任意のバイナリデータを入れることができる。 この3つのデータから、機械学習を行う際に必要となる特徴量を抽出するのが、このデータ変換モジュールである。 また、効率を重視して、それぞれのkey-valueは、各言語のmap型や辞書型を利用せず、keyとvalueのペアの配列で表現される。
以下に例を示す。
(
[
("user/id", "ippy"),
("user/name", "Loren Ipsum"),
("message", "<H>Hello World</H>")
],
[
("user/age", 29.0),
("user/income", 100000.0)
],
[
("user/image", "xxxxxxxx")
]
)
キーの名前に "$" 記号を含めることはできない。
例えばC++から利用する場合、datumは std::vector<std::pair<std::string, std::string> > 、 std::vector<std::pair<std::string, double> > 、 std::vector<std::pair<std::string, std::string> > の3つの要素からなっている。
ここでは、 std::pair<T,U> をPython風のタプルで、 std::vector<T> をPython風のリストで表している。
データ変換の流れ¶
大まかな処理の流れは以下のようになっている。
datumは文字列データ、数値データ、バイナリデータの3つがあるため、それぞれが別々の処理フローを流れる。
文字列データには、まずstring_filter_rulesが適用されて、フィルター済みデータが追加される。 その状態で、string_rulesによって文字列データからの特徴量が抽出される。
数値データには、まずnum_filter_rulesが適用されて、フィルター済みデータが追加される。 その状態で、num_rulesによって数値データからの特徴量が抽出される。
バイナリデータにはbinary_rulesによって特徴量が抽出される。
フィルターと特徴抽出器には引数を必要とするものもあるため、それらはtypesで事前に準備することによって各規則で利用することができるようになる。
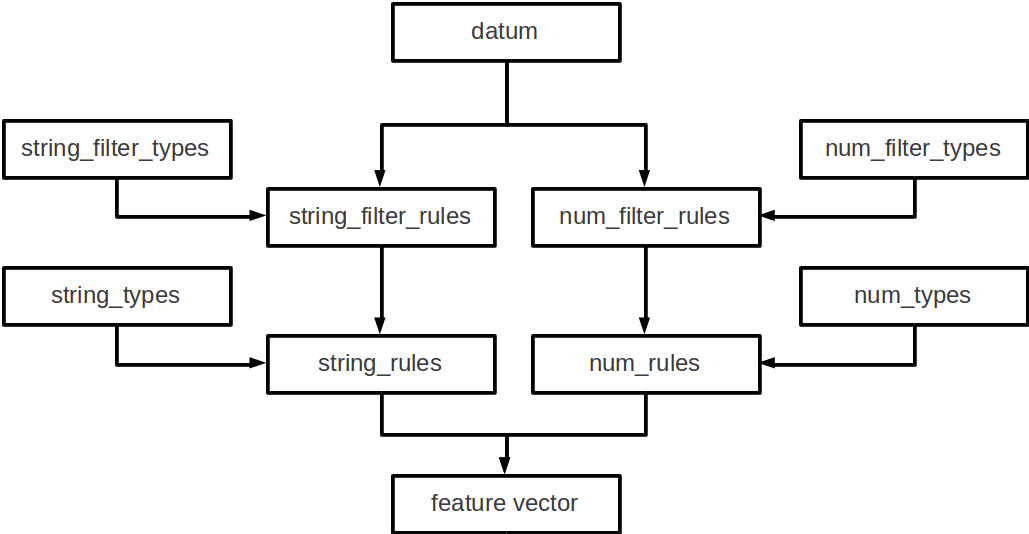
図: 変換エンジンの構成
フィルター¶
Jubatusはフィルターという機能を用いて、datum中のkey-valueペアを変換して、別の要素として追加することができる。 例えば、元のデータがHTMLで書かれていたとしよう。 この中のタグ文字列(<a> など)は、学習時には邪魔になることがおおく、そのため予めフィルタリングして使いたいことがある。 あるいは、メール本文の引用(>から始まる行)を削除したいこともあるだろう。 こうした時に利用するのが、filter機能である。
例として、"message"内の文字列からHTMLタグを取り除く。
まず、「HTMLタグを取り除く」というルールを定義し、それを key = "message" に適用する。
これは、以下のようなconfigで表現される。
"string_filter_types": {
"detag": { "method": "regexp", "pattern": "<[^>]*>", "replace": "" }
},
"string_filter_rules": [
{ "key": "message", "type": "detag", "suffix": "-detagged" }
]
まず、"string_filter_types"でフィルターを定義し、これを "detag" と命名する。 "detag" フィルターに対して、"regexp"という手法で、"<[^>]*>"を""に置き換える、というフィルターを定義する。 次に、実際にdatumのどの要素にどう適用するのか書いたのが"string_filter_rules"である。 ここでは、"message"という名前の"key"の要素に対して、先で定義した"detag"フィルターを適用し、"message"に"-detagged"を付与したkey、すなわち"message-detagged"に結果を格納することを示している。
また、"age"を数え年に変換(+1歳に)するには、
"num_filter_types": {
"add_1": { "method": "add", "value": "1" }
},
"num_filter_rules": [
{ "key": "user/age", "type": "add_1", "suffix": "_kazoe" }
]
とする。この挙動も先と同じで、"user/age"に1加えた結果が"user/age_kazoe"に格納される。
これらのfilterを通すことにより、次の datum が得られる:
(
[
("user/id", "ippy"),
("user/name", "Loren Ipsum"),
("message", "<H>Hello World</H>"),
("message-detagged", "Hello World")
],
[
("user/age", 29.0),
("user/age_kazoe", 30.0),
("user/income", 100000.0)
]
)
それぞれの要素について、詳細に説明する。 なお、これらの各 "types" や "rules" は省略可能で、省略した場合はそれぞれ何も指定されていないものとして扱われる。
string_filter_types¶
<フィルター名>: <引数> からなる辞書を指定する。 フィルター名は文字列、引数は文字列から文字列への辞書である。 引数には必ず"method"を指定する。 残りの引数に関しては、"method"の内容に応じて必要な引数が異なる。 指定できる"method"の値と、それぞれに対応した引数は以下のとおりである。
-
regexp 正規表現にマッチした部分を、指定した文字列に変換する。
pattern: マッチさせる正規表現を指定する。 replace: 置き換え後の文字列を指定する。 利用できる正規表現は、使用する正規表現エンジンのドキュメント (oniguruma または re2) を参照すること。 使用する正規表現エンジンはコンパイル時に選択可能である (バイナリパッケージでインストールした場合は oniguruma が使用される)。
HTMLのすべてのタグを消すには、例えば以下のようなstring_filter_typeを宣言すればよいだろう。
"string_filter_types": { "detag": { "method": "regexp", "pattern": "<[^>]*>", "replace": "" } }
-
dynamic プラグインを利用する。詳細は後述する。
path: プラグインのパスを指定する。 function: プラグインの呼び出し関数を指定する。この値はプラグインによって異なる。
string_filter_rules¶
フィルターの適用規則を指定する。 規則は指定された順に評価される。 datum がある規則の条件を満たした場合、そのルールが適用され、変換後の値が datum に追加される。 規則は、元の datum と、それまでにフィルター規則で追加された値の両方に適用される。 各規則は"key", "except" (オプション), "type", "suffix"の要素からなる辞書を指定する。
key: datumの各要素のどのkeyとマッチさせるかを指定する。詳細は後述する。 except: key のマッチから除外するパターンを指定する。このパラメタは省略可能である。この詳細は後述する。 type: 利用するフィルター名を指定する。これは "string_filter_types" の項で作ったフィルター名を指定する。デフォルトで利用できるフィルターはない。 suffix: 変換後の結果を格納するkeyのサフィックスを指定する。例えばsuffixに"-detagged"が指定され、"name"という名前のkeyに規則が適用された場合、結果は"name-detagged"という名前のkeyに格納される。
"key"および"except"の要素は以下のうちのいずれかのフォーマットで指定する。 但し、datumの全要素に対して、すべての規則が適用されるかチェックされる。 したがって、複数の規則がマッチした場合は両方の規則が適用されて、複数のフィルター済みの値が追加されることに注意する。 なお、"key"および"except"に関しては以降でも登場するが、全て同じフォーマットであり、複数適用される可能性がある点も同様である。
値 意味 "*" or "" 全ての要素にマッチする。"key"にこれが指定されると必ず適用されることになる。 "XXX*" 末尾に*をつけると、その前のみをプレフィックスとして使用する。つまり、"XXX"で始まるkeyのみにマッチする。 "*XXX" 先頭に*をつけると、その後のみをサフィックスとして使用する。つまり、"XXX"で終わるkeyのみにマッチする。 "/XXX/" 2つのスラッシュ(/)で囲うと、その間の表現を正規表現とみなして、正規表現でマッチする。 その他 以上のいずれでもない場合は、与えられた文字列と一致するkeyのみにマッチする。
"except" が与えられ、かつ "key" と "except" の双方にマッチした場合は、そのルールはスキップされる。 例えば、{"key": "*", "except": "foo", ... } のようにすれば「"foo" 以外のすべてのキーにマッチする規則」を定義することができる。
num_filter_types¶
"string_filter_types" と同様、<フィルター名>: <引数> からなる辞書を指定する。 利用の仕方はstring_filter_typesとほぼ同じである。 <フィルター名> は文字列、引数は文字列から文字列への辞書である。 <引数> には必ず"method"を指定し、残りの引数は"method"の値に応じて必要なものが異なる。 指定できる"method"の値と、それぞれに対応した引数は以下のとおりである。
-
add 元の値に指定した値を足す。
value: 足す値の文字列表現を指定する。例えば3足すのであれば、"3"と指定する。数値型ではなく文字列として指定する点に注意すること。内部的には Double として利用される。
-
linear_normalization 値を0以上から1以下の小数へと正規化する。 "min"と"max"の2つの小数を入力として要求し、これら2つのパラメータの省略はできない。 入力された値xに対して「(x - min) / (max - min)」という計算を行う事で0以上1以下の小数へと線形に変換する。 もしxが"min"より小さい場合には0へ切り上げられる。 同様にxが"max"より大きい場合には1へ切り捨てられる。 この挙動は"truncate"オプションにより変更が可能である。 "max"が"min"より小さい場合は、invalid_parameter例外が発生し失敗する。
min: 想定される最小値を指定する。例えば最小値が0であれば、"0"と指定する。数値型ではなく文字列として指定する点に注意すること。内部的には Double として利用される。省略不可。 max: 想定される最小値を指定する。例えば最大値が100であれば、"100"と指定する。数値型ではなく文字列として指定する点に注意すること。内部的には Double として利用される。"min"より小さい数や等しい値は指定できない。省略不可。 truncate: 最小値未満の値や、最大値以上の値に対する動作を規定する。デフォルトでは"True"であり、最小値以下の値は0へ、最大値以上の値は1へ切り詰められる。"True"以外を指定する事で最小値以下・最大値以上の値に対する切り詰め処理を行わせない事ができる。省略可能。 この機能を使う際のコンフィグの一例は以下の通りである。
"num_filter_types" : {
"zero_to_hundred": { "method": "linear_normalization", "min": "0", "max":"100" }
},
"num_filter_rules" : [
{"key" : "*", "type": "zero_to_hundred", "suffix": "linear_normalized" }
],
-
gaussian_normalization 値がガウス分布(正規分布)していると仮定し、与えられた平均値と標準偏差にそった値を-1以上+1以下の範囲の小数に正規化する。 "average"と"standard_deviation"の2つの小数を入力として要求し、省略はできない。 入力された値xに対して「(x - average) / standard_deviation」という計算を行う事で-1以上1以下の小数へと変換する。 そのため外れ値は-1を下回る値や1を超える値になることがありうる。 "standard_deviation"に負の値を指定した場合にはinvalid_parameter例外が発生し失敗する。
average: 平均値を指定する。例えば平均値が80であれば、"80"と指定する。数値型ではなく文字列として指定する点に注意すること。内部的には Double として利用される。 standard_deviation: 想定される標準偏差を指定する。例えば標準偏差が2.3であれば、"2.3"と指定する。数値型ではなく文字列として指定する点に注意すること。内部的には Double として利用される。 この機能を使う際のコンフィグの一例は以下の通りである。
"num_filter_types" : {
"gaussian_80_2.3": { "method": "gaussian_normalization", "average": "80", "standard_deviation":"2.3" }
},
"num_filter_rules" : [
{"key" : "*", "type": "gaussian_80_2.3", "suffix": "gaussian_normalized" }
],
-
sigmoid_normalization 値をシグモイド関数に基づいて0から1の範囲へと切り詰める。 "gain"と"bias"の2つを入力として要求する。省略した場合にはそれぞれ1と0になる。 入力された値xに対して「1 / (1 + e ^ (-gain * (x - bias)))」という計算を行う事で0〜1の小数へと変換する。
gain: sigmoid関数のゲイン値を指定する。大きな値を指定するほど急峻なsigmoid関数となる。例えば0.5を指定する場合は"0.5"と指定する。数値型ではなく文字列として指定する点に注意すること。内部的には Float として利用される。省略可能であり、デフォルトでは1である。 bias: sigmoid関数のバイアス値を指定する。sigmoid関数が0.5を出力する事を期待するxの値を指定する。例えば3を指定する場合は"3"と指定する。数値型ではなく文字列として指定する点に注意すること。内部的には Float として利用される。省略可能であり、デフォルトでは0である。 この機能を使う際のコンフィグの一例は以下の通りである。
"num_filter_types" : {
"sigmoid": { "method": "sigmoid_normalization", "gain": "0.05", "bias":"5" }
},
"num_filter_rules" : [
{"key" : "*", "type": "sigmoid", "suffix": "sigmoid_normalized" }
],
-
dynamic プラグインを利用する。詳細は後述する。
path: プラグインのパスを指定する。 function: プラグインの呼び出し関数を指定する。
num_filter_rules¶
こちらも、string_filter_rules同様、フィルターの適用規則を指定する。 規則は複数からなり、各規則は"key", "except" (オプション), "type", "suffix"の要素からなる辞書を指定する。
key: datumの各要素のどのkeyとマッチさせるかを指定する。詳細はstring_filter_rulesを参照のこと。 except: key のマッチから除外するパターンを指定する。このパラメタは省略可能である。詳細はstring_filter_rulesを参照のこと。 type: 利用するフィルター名を指定する。これはstring_filter_typesの項で作ったフィルター名を指定する。デフォルトで利用できるフィルターはない。 suffix: 変換後の結果を格納するkeyのサフィックスを指定する。
"key"と"except"の指定の仕方は、string_filter_rulesを参照のこと。
文字列からの特徴抽出¶
文字列型に対する特徴抽出器と、その抽出規則の適用方法について解説する。
以下に、設定の例を示す。 この例では、"user/name"の値はそのまま特徴量として使用し、"message"は文字2グラムを特徴量とし、"message-detagged"はスペース文字で分割した単語を特徴量とする。
"string_types": {
"bigram": { "method": "ngram", "char_num": "2" }
},
"string_rules": [
{ "key": "user/name", "type": "str", "sample_weight": "bin", "global_weight": "bin" },
{ "key": "message", "type": "bigram", "sample_weight": "tf", "global_weight": "bin" },
{ "key": "message-detagged", "type": "space", "sample_weight": "bin", "global_weight": "bin" }
]
例えば、この規則を次のような datum に適用する。
(
[
("user/id", "ippy"),
("user/name", "Loren Ipsum"),
("message", "<H>Hello World</H>"),
("message-detagged", "Hello World")
],
[]
)
結果として得られる特徴抽出結果は、以下のようになる。 "message" は "bigram" 設定なので2文字ずつに分割され、特徴量 "H>" は文字列中に2度出てくるのでその重みは2になることがわかる。
| キー | 文字列 | 特徴量 | 重み |
|---|---|---|---|
| "user/name" | "Loren Ipsum" | "Loren Ipsum" | 1 |
| "message" | "<H>Hello World</H>" | "<H" | 1 |
| "H>" | 2 | ||
| ">H" | 1 | ||
| "He" | 1 | ||
| "el" | 1 | ||
| "ll" | 1 | ||
| "lo" | 1 | ||
| "o " | 1 | ||
| " W" | 1 | ||
| "Wo" | 1 | ||
| "or" | 1 | ||
| "rl" | 1 | ||
| "ld" | 1 | ||
| "d<" | 1 | ||
| "</" | 1 | ||
| "/H" | 1 | ||
| "message-detagged" | "Hello World" | "Hello" | 1 |
| "World" | 1 |
string_types¶
string_typesで文字列特徴抽出器を定義する。 主に、パスなどの引数を指定しなければならない特徴抽出器は、一度string_typesで指定してから利用しなければならない。 string_filter_typesなどと同様、<抽出器名>:<引数> からなる辞書を指定する。 抽出器名に "@" 文字を含むことはできない。 引数は文字列から文字列への辞書で、必ず"method"を指定する必要がある。 それ以外に必要な引数は"method"に応じて異なる。
指定できる"method"の値と、それぞれに対応した引数は以下のとおりである。
-
ngram 隣接するN文字を特徴量として利用する。こうした特徴量は文字N-gram特徴と呼ばれる。
char_num: 利用する文字数(整数値)の文字列表現を指定する。文字数は0より大きい必要がある。内部的には Integer として利用される。 例として、連続する2文字および3文字を特徴として利用する、bigramとtrigramを定義する方法を記す。
"string_types": { "bigram": { "method": "ngram", "char_num": "2" }, "trigram": { "method": "ngram", "char_num": "3" } }
-
regexp 与えられた文書から正規表現を利用してキーワードを抜き出して、それぞれを特徴量として利用する。 正規表現マッチは連続的に行われ、マッチした箇所全てを特徴として使う。
pattern: マッチさせる正規表現を指定する。 group: キーワードとして取り出すグループを指定する。0ならマッチした全体で、1以上の値を指定すると () で取り出したグループだけをキーワードとする。省略すると0として扱う。 利用できる正規表現は、使用する正規表現エンジンのドキュメント (oniguruma または re2) を参照すること。 使用する正規表現エンジンはコンパイル時に選択可能である (バイナリパッケージでインストールした場合は oniguruma が使用される)。
最も簡単な例として、以下では日付表現 (YYYY/MM/DD) を全て取り出す。
"string_types": { "date": { "method": "regexp", "pattern": "[0-9]{4}/[0-9]{2}/[0-9]{2}" } }
パターンの一部だけを利用するときは、 "group" 引数を利用する。たとえば、以下の様な設定で年齢が取れるだろう。
"string_types": { "age": { "method": "regexp", "pattern": "(age|Age)([ :=])([0-9]+)", "group": "3" } }
-
split 指定した文字を区切り文字として文字列を分割し、それぞれを特徴量として利用する。
separators: 区切り文字として利用する文字を指定する。複数の文字を指定した場合はそれぞれを区切り文字とする。 例として、カンマを区切り文字として利用する場合、およびa,b,cの3文字を区切り文字として利用する場合に定義する方法を記す。
"string_types": { "comma_split": { "method": "split", "separators": "," }, "abc_split": { "method": "split", "separators": "abc" } }
-
dynamic プラグインを利用する。詳細は後述する。
path: プラグインのパスを指定する。 function: プラグインの呼び出し関数を指定する。
string_rules¶
文字列特徴の抽出規則を指定する。 string_filter_rulesなどと同様、複数の規則を羅列する。 各規則は、"key", "except" (オプション), "type", "sample_weight", "global_weight"からなる辞書で指定する。 文字列データの場合、与えられた文字列から特徴量を抽出し、そこに対して重みを設定する必要がある。 重みの設定の仕方を決めるのが、"sample_weight"と"global_weight"の2つのパラメータである。 実際に利用する重みは、2つの重みの積を重み付けとして利用する。
key: datumの各要素のどのkeyとマッチさせるかを指定する。string_filter_rulesを参照のこと。なお、 "*" や "" を設定した場合、フィルタ処理前の要素も特徴抽出対象となるため注意する。
except: key のマッチから除外するパターンを指定する。このパラメタは省略可能である。詳細はstring_filter_rulesを参照のこと。
type: 利用する抽出器名を指定する。これはstring_typesの項で作った抽出器名を指定する。また、以下の抽出器はデフォルトで利用できる。
値 意味 "str"文字列分割を行わず、指定された文字列そのものを特徴として利用する。 "space"スペース文字で分割を行い、分割された部分文字列を特徴として利用する。 sample_weight: 各key-value毎の重み設定の仕方を指定する。これはkey-value一つに対して決定される重みである。
値 意味 "bin"重みを常に1とする。 "tf"与えられた文字列中で出現する回数で重み付けをする。例えば5回"hello"が出現したら、重みを5にする。 "log_tf"tfの値に1を足してlogを取った値を重み付けに利用する。例えば5回"hello"が出現したら、重みはlog(5 + 1)にする。 global_weight: 今までの通算データから算出される、大域的な重み付けを指定する。
値 意味 "bin"重みを常に1とする。 "idf"文書正規化頻度の逆数の対数を利用する。例えば文書1000件中で50件にその特徴が含まれた場合、重みはlog(1000/50)にする。大まかには出現頻度の少ない特徴ほど大きな重みが設定される。 "idf1""idf"の値に 1.0 を加算した値を使用する。表下の説明も参照のこと。"bm25"Okapi BM25 による重み付けを利用する。特徴の出現頻度だけでなく、その特徴が出現した文書の長さを考慮して重み付けを行う。大まかには、出現頻度が少なく、かつ出現した文書の長さが短い特徴ほど、大きな重みが設定される。通常は "sample_weight": "tf"とセットで使用する。経験的には IDF よりも良い結果が得られることが多い。IDF よりも計算量が大きくなる点に留意すること。
sample_weightとglobal_weightは、ともにbinにしておいても通常のケースでは正しく動作する。 また、例えば分類問題など重み自体を学習するケースでは、ともにbinにしておいても自動的に調整される。
global_weight において、 "idf" の代わりに "idf1" を使用することで、最初の文書に出現する特徴や全ての文書に出現する特徴が学習モデルに登録されない問題を回避することができる。
通常の "idf" の場合、最初の文書(例えばRecommenderにおいて最初に登録したレコード)の特徴や、すべての文書に出現する特徴(例えば "the" という単語が文書1,000件中で1,000件に含まれた場合)、それらの特徴のIDF値が 0 すなわち特徴の重みが 0 となってしまい、学習が行われない。
"idf1" は IDF値 + 1.0 を重みとして使うことで、そのような状況でも特徴の学習を行うことができるようにしている。
数値からの特徴抽出¶
数値型に対しても、文字列型同様変換ルールを記述する。 また、数値型に関しても、ユーザー定義の変換器を定義することができる。
以下に、設定の例を示す。
"num_types": {
},
"num_rules": [
{ "key": "user/age", "type": "num" },
{ "key": "user/income", "type": "log" },
{ "key": "user/age_kazoe", "type": "num" }
]
例えば、この規則を次のような datum に適用する。
(
[],
[
("user/age", 29),
("user/income", 100000),
("user/age_kazoe", 30)
]
)
結果として得られる特徴抽出結果は、以下のようになる。
| キー | 値 | 重み |
|---|---|---|
| "user/age" | 29 | 29 |
| "user/income" | 100000 | log(100000) = 11.5129... |
| "user/age_kazoe" | 30 | 30 |
num_types¶
num_typesで数値データに対する特徴抽出器を定義する。 string_typesなどと同様、<抽出器名>: <引数> からなる辞書を指定する。 引数は文字列から文字列への辞書で、必ず"method"を指定する必要がある。 それ以外に必要な引数は"method"に応じて異なる。 指定できる"method"の値と、それぞれに対応した引数は以下のとおりである。
-
dynamic プラグインを利用する。詳細は後述する。
path: プラグインのパスを指定する。 function: プラグインの呼び出し関数を指定する。
num_rules¶
数値特徴の抽出規則を指定する。 string_rulesなどと同様、複数の規則を羅列する。 各規則は、"key", "except" (オプション), "type"からなる辞書で指定する。 重みの付け方や特徴名の指定の仕方もそれぞれの"type"ごとに異なる。
key: datumの各要素のどのkeyとマッチさせるかを指定する。詳細はstring_filter_rulesを参照のこと。なお、"*" や "" を設定した場合、フィルタ処理前の要素も特徴抽出対象となるため注意する。
except: key のマッチから除外するパターンを指定する。このパラメタは省略可能である。詳細はstring_filter_rulesを参照のこと。
type: 利用する抽出器名を指定する。これはnum_typesの項で作った抽出器名を指定する。ただし、以下の抽出器はデフォルトで利用できる。
値 意味 "num"与えられた数値をそのまま重みに利用する。 "log"与えられた数値の自然対数を重みに利用する。但し、数値が1以下の場合は0とする。 "str"与えられた数値を文字列として扱う。これは、例えばIDなど、数値自体の大きさに意味のないデータに対して利用する。重みは1とする。
バイナリデータからの特徴抽出¶
binary_types¶
binary_typesでバイナリデータに対する特徴抽出器を定義する。 string_typesなどと同様、 <抽出器名>: <引数> からなる辞書を指定する。 引数は文字列から文字列への辞書で、必ず"method"を指定する必要がある。 それ以外に必要な引数は"method"に応じて異なる。 指定できる"method"の値と、それぞれに対応した引数は以下のとおりである。
-
dynamic プラグインを利用する。詳細は後述する。
path: プラグインのパスを指定する。 function: プラグインの呼び出し関数を指定する。
binary_rules¶
バイナリ特徴の抽出規則を指定する。 string_rulesなどと同様、複数の規則を羅列する。 各規則は、"key", "except" (オプション), "type"からなる辞書で指定する。 重みの付け方や特徴名の指定の仕方もそれぞれの"type"ごとに異なる。
key: datumの各要素のどのkeyとマッチさせるかを指定する。詳細はstring_filter_rulesを参照のこと。 except: key のマッチから除外するパターンを指定する。このパラメタは省略可能である。詳細はstring_filter_rulesを参照のこと。 type: 利用する抽出器名を指定する。これはbinary_typesの項で作った抽出器名を指定する。デフォルトで利用できる特徴抽出器はないため、必ずbinary_typesで指定する必要がある。
組み合わせ特徴量による特徴抽出¶
数値特徴量や文字列特徴量の組み合わせにより、新たな特徴量を抽出することができる。
以下に、設定の例を示す。 この例では、数値型の特徴量の和("add")と積("mul")を新たな特徴量とする。 また、文字列型の特徴量を"bin/bin"で変換した特徴量の和("add")と積("mul")を新たな特徴量とする。
"num_types": {},
"num_rules": [
{"key": "*", "type": "num"}
],
"string_types": {},
"string_rules": [
{"key": "*": "type": "str", "sample_weight": "bin", "global_weight": "bin"},
],
"combination_types": {},
"combination_rules": [
{ "key_left": "*@num", "key_right": "*@num", "type": "add"},
{ "key_left": "*@num", "key_right": "*@num", "type": "mul"},
{ "key_left": "*@str#bin/bin", "key_right": "*@str#bin/bin", "type": "add"}
{ "key_left": "*@str#bin/bin", "key_right": "*@str#bin/bin", "type": "mul"}
]
例えば、この規則を次のようなdatumに適用する。
(
[],
[
("user/age", 25),
("user/income", 1000),
("user/name", "Loren"),
("message", "Hello")
]
)
結果として得られる特徴抽出結果は、以下のようになる。 "num_rules", "string_rules"で抽出された特徴量に対して、 "combination_rules"によって特徴量の和と積が計算されているのがわかる。
| キー | 重み |
|---|---|
| "user/age@num" | 25 |
| "user/income@num" | 1000 |
| "user/income@num&user/age@num/add" | 1025 |
| "user/income@num&user/age@num/mul" | 25000 |
| "message$Hello@str#bin/bin" | 1 |
| "user/name$Loren@str#bin/bin" | 1 |
| "message$Hello@str#bin/bin&user/name$Loren@str#bin/bin/mul" | 1 |
| "message$Hello@str#bin/bin&user/name$Loren@str#bin/bin/add" | 2 |
combination_types¶
combination_types で組み合わせデータに対する特徴抽出器を定義する。 string_typesなどと同様、<抽出器名>: <引数> からなる辞書を指定する。 引数は文字列から文字列への辞書で、必ず"method"を指定する必要がある。 それ以外に必要な引数は"method"に応じて異なる。 指定できる"method"の値と、それぞれに対応した引数は以下のとおりである。
-
dynamic プラグインを利用する。詳細は後述する。
path: プラグインのパスを指定する。 function: プラグインの呼び出し関数を指定する。
combination_rules¶
組み合わせ特徴量の抽出規則を指定する。 string_rulesなどと同様、複数の規則を羅列する。 各規則は、"key_left", "key_right", "except_left" (オプション), "except_right" (オプション), "type"からなる辞書で指定する。 重みの付け方や特徴量の指定の仕方もそれぞれの"type"ごとに異なる。
key_left: 第一引数。datumの各要素のどのkeyとマッチさせるかを指定する。詳細はstring_filter_rulesを参照のこと。なお、"*" や "" を設定した場合、フィルタ処理前の要素も特徴抽出対象となるため注意する。
key_right: 第二引数。同上。
except_left: 第一引数の除外パターン。 key のマッチから除外するパターンを指定する。このパラメタは省略可能である。詳細はstring_filter_rulesを参照のこと。
except_right: 第二引数の除外パターン。同上。
type: 利用する抽出器名を指定する。これはcombination_typesの項で作った抽出器名を指定する。ただし、以下の抽出器はデフォルトで利用できる。
値 意味 "add""key_left" と "key_right" で指定された特徴量の和を重みに利用する。 "mul""key_left" と "key_right" で指定された特徴量の積を重みに利用する。
特徴ベクトルのキーのハッシュ化¶
Jubatus では特徴ベクトルのキーをハッシュ化することでメモリ消費を抑えることができる。 特徴ベクトルのキーをハッシュ化することで、特徴ベクトルの次元数の最大長を制限することができるが、ハッシュの衝突により学習精度の低下が発生する可能性がある。
この機能はデフォルトでは無効である。
使用するには、変換設定に hash_max_size を指定する。値には0より大きい整数値を指定する。
{
"string_filter_types": {},
"string_filter_rules": [],
"num_filter_types": {},
"num_filter_rules": [],
"string_types": {},
"string_rules": [{"key": "*", "type" : "str", "sample_weight": "bin", "global_weight" : "bin"}],
"num_types": {},
"num_rules": [{"key" : "*", "type" : "num"}],
"binary_types": {},
"binary_rules": [],
"hash_max_size": 16
}
最適な hash_max_size の値は、使用するデータセットおよび環境により異なる。
hash_max_size が制限するのは入力される datum のキー数ではなく、(変換後の) 特徴ベクトルのキー数であることに注意する。
プラグイン¶
フィルターと抽出器では、それぞれプラグインを利用することができる。 プラグインは単体の動的ライブラリファイル(.soファイル)からなる。 プラグインの作り方は、別の章を参照するとして、ここではプラグインの使い方について解説する。
各フィルターと抽出器のいずれの場合も、プラグインの指定の仕方は同じである。
CLASS_types (CLASS は string または num) で、フィルターや抽出器を指定する際のパラメータで、"method"に"dynamic"を、"path"に.soファイルへのパスを、"function"に各プラグイン固有の呼び出し関数名を指定する。
プラグインのパスの指定方法は2種類ある。
パス名に '/' が含まれる場合は、相対パスか絶対パスとみなされる。
この場合、相対パスならカレントディレクトリからの相対パスの、絶対パスなら指定のパスのプラグインを読み込む。
逆に '/' が含まれない場合は、以下の順で読み込みを試み、成功したほうが採用される。
- 環境変数
JUBATUS_PLUGIN_PATHで指定されたディレクトリ - ビルド時に指定したデフォルトのプラグインディレクトリ(多くの場合は
$PREFIX/lib/jubatus/pluginまたは$PREFIX/lib64/jubatus/plugin)
また、その他のパラメータに関しては、各プラグイン固有のパラメータを渡す。
Jubatusでは、デフォルトで以下の2つの文字列特徴量のプラグインと1つの画像特徴量プラグインが提供されている。 ただし、コンパイルオプションによっては一部のプラグインがビルドされないため、注意すること。
文字列特徴量プラグイン¶
文字列特徴量プラグインではMeCabプラグインとuxプラグインを提供している。
-
libmecab_splitter.so string_typesで指定できる。 MeCab を利用して文書を単語分割し、各単語を特徴量として利用する。
--enable-mecabオプション付きでコンパイルした場合のみ利用可能である。 バイナリパッケージでもこのプラグインは利用可能である。function: "create"を指定する。 arg: MeCabエンジンに渡す引数を指定する (例えば、以下の例では -d で辞書ファイルのディレクトリを指定している)。この指定がないと、MeCabのデフォルト設定で動作する。 引数の指定の仕方は、 MeCab のドキュメント を参照すること。 ngram: MeCabによる単語分割の結果に基づいて構築する形態素N-gramの N を指定する。 この指定がないと、 N に 1 が指定されたものと見なされる (つまり形態素N-gramを構築せず、各形態素をそのまま特徴量として使用する)。 N は数値ではなく文字列として指定する点に注意する (以下の例を参照)。 base: 各形態素の原形を使用するかどうかを指定する。 原形を使用する場合は "true" を、表層を使用する場合は "false" を指定する。 "true" を指定した場合でも、原形がない形態素 (固有名詞など) については表層を使用する。 この指定がないと、"false" が指定されたものと見なされる。 "true", "false" は文字列として指定する点に注意する (以下の例を参照)。 include_features: 使用する形態素のパターンを指定する。 MeCab の形態素解析結果の CSV 表現 (例: 名詞,固有名詞,組織,*,*,*,*) にマッチするパターンをstring_filter_rulesのkeyと同様のフォーマットで指定する。 例えば、名詞だけを抽出する場合は"名詞,*"のように指定する。 複数の品詞を使用したい場合は、パターンを|で区切って指定する (例:"名詞,*|動詞,*")。 この指定がないと、"*" が指定されたものと見なされる (すべての品詞が使用される)。exclude_features: 除外する形態素のパターンを指定する。 指定方法は include_featuresと同様である。include_featuresとexclude_featuresが同時に指定された場合、include_featuresにマッチしexclude_featuresにマッチしない品詞のみが抽出される。 この指定がないと、"" が指定されたものと見なされる (除外を行わない)。"string_types": { "mecab": { "method": "dynamic", "path": "libmecab_splitter.so", "function": "create", "arg": "-d /usr/lib64/mecab/dic/ipadic", "ngram": "1", "base": "false", "include_features": "*", "exclude_features": "" } }
-
libux_splitter.so string_typesで指定できる。 ux-trie を利用して、与えられた文書から最長一致で辞書マッチするキーワードを抜き出して、それぞれを特徴量として利用する。 単純な最長一致なので、高速だが精度が悪い可能性がある点には注意すること。
--enable-uxオプション付きでコンパイルした場合のみ利用可能である。 バイナリパッケージでもこのプラグインは利用可能である。function: "create"を指定する。 dict_path: 1行1キーワードで書かれたテキスト形式の辞書ファイルを、フルパスで指定する。 "string_types": { "ux": { "method": "dynamic", "path": "libux_splitter.so", "function": "create", "dict_path": "/path/to/keyword/dic.txt" } }
画像特徴量プラグイン¶
画像特徴量プラグインではOpenCVプラグインを提供している。
-
libimage_feature.so
binary_typesで指定できる。OpenCV を利用して、与えられた画像から特徴量を抜き出して利用する。
--enable-opencv オプション付きでコンパイルした場合のみ利用可能である。
バイナリパッケージでもこのプラグインは利用可能である。
function: "create"を指定する。
algorithm: 利用する特徴量記述アルゴリズムを指定する。画像特徴量抽出プラグインでは、下記の2つのアルゴリズムを提供している。なお、いずれもキーポイントの抽出はDense sampling (すべての画素について特徴量を抽出する手法) で行っている。
値 意味 "RGB"画素のRGB値を抽出する "ORB"パッチ内で選ばれた2点の輝度差によってバイナリ列を作る。詳細は OpenCVドキュメント を参照。 resize: 画像をリサイズするかどうかを決定する。リサイズする場合は "true" を指定し、しない場合は "false" を指定する。デフォルトでは "false" が指定される
x_size: 画像の幅を指定しリサイズする。
resizeが "true" のときのみ有効y_size: 画像の高さを指定しリサイズする。
resizeが "true" のときのみ有効"binary_types": { "image": { "method": "dynamic", "path": "libimage_feature.so", "algorithm":"ORB", "resize":"true" "x_size":"120.0" "y_size":"120.0" "function": "create", } }
Python Bridge¶
Python Bridge を使用すると、C++ でプラグインを作成しなくても、特徴抽出ロジックを Python で記述することができる。 現在、以下のブリッジインタフェースが利用できる。
インタフェース 用途 string_feature文字列に対する特徴抽出。 ( string_types)word_splitter文字列に対する特徴抽出 (部分文字列の抽出のみ)。 ( string_types)num_feature数値に対する特徴抽出。 ( num_types)binary_featureバリナリデータに対する特徴抽出。 ( binary_types)
設定¶
Python Bridge はプラグイン形式で提供されている。
-
libpython_bridge.so string_types,num_types,binary_typesで指定できる。--enable-python-pluginまたは--enable-python3-pluginオプション付きでコンパイルした場合のみ利用可能である。 バイナリパッケージ (RHEL 6 を除く) でもこのプラグインは利用可能である。function: 上記のインタフェース名を指定する (例: string_feature)。module: Pythonモジュール名を指定する。 class: Pythonモジュール内のクラス名を指定する。 "num_types": { "multiply_by_3": { "method": "dynamic", "path": "libpython_bridge.so", "function": "num_feature", "module": "number_multiplier", "class": "NumberMultiplier", "n": "3" } }
上記に加えて、Pythonクラスに渡す任意のパラメタを指定することができる。 パラメタのキーとバリューは共に文字列型である必要がある。
Python モジュールに対する共通要件¶
Python で特徴抽出ロジックを実装する場合、Pythonクラスをモジュールに定義する必要がある。 以下に例を示す。
class MyFeatureExtractor(object):
@classmethod
def create(cls, param):
return cls()
def extract(self, key, value):
return [(u'key1', 1.0), (u'key2', 2.0)]
Pythonクラスに対する要件を以下に示す。
- クラスは
createクラスメソッドを実装する必要がある。 引数paramは、設定ファイルで指定されたパラメタ (dict型) である。 - 各クラスは、各インタフェースで要求されているシグネチャのインスタンスメソッドを実装する必要がある。 以下の各セクションを参照のこと。
- モジュールは、
sys.path内のいずれかのパス、PYTHONPATH環境変数内のいずれかのパス、またはデフォルトの Python モジュールディレクトリ ($PREFIX/lib/jubatus/python) のいずれかに配置されている必要がある。 バイナリパッケージでインストールした Python Bridge はpyenvを認識しないため注意すること。pyenvでインストールした Python パッケージを利用したい場合は、Jubatus プロセスを開始する前にPYTHONPATHを定義すること (例:export PYTHONPATH="$HOME/.pyenv/versions/3.5.1/lib/python3.5/site-packages")。
Python コードでエラーが発生した場合は標準エラー出力に出力される。
以下の各セクションでは、Python 3.x の型名で説明を行う。
Python 2.x を使用している場合は、 str と bytes は unicode と str にそれぞれ読み替えること。
string_feature インタフェース¶
クラスにインスタンスメソッド extract (1 引数) を定義する必要がある。
引数は入力のテキストである (
str型)。戻り値は 4 要素のタプルのリストである。タプルの各要素の意味は以下の通りである。
- 抽出したデータの開始位置 (
int型);0でも良い。 - 抽出したデータの長さ (
int型);0でも良い。 - 抽出した文字列データ (
str型)。 - 抽出した文字列データに対するスコア (
double型); 通常は1.0を使用すれば良い。
- 抽出したデータの開始位置 (
def extract(self, text):
return [(0, 0, text, 1.0)]
サンプルとして、英語の文章に対するステミング (Porter Stemmer) を行う実装がデフォルトで提供されている。
詳細は sentence_stemmer モジュール のソースを参照すること。
このサンプルを動作させるには Natural Language Toolkit のインストールが必要である (pip install nltk)。
"string_types": {
"stem_sentence": {
"method": "dynamic",
"path": "libpython_bridge.so",
"function": "string_feature",
"module": "sentence_stemmer",
"class": "SentenceStemmer"
}
},
"string_rules": [
{ "key": "*", "type": "stem_sentence", "sample_weight": "tf", "global_weight": "bin" }
]
word_splitter インタフェース¶
クラスにインスタンスメソッド split (1 引数) を定義する必要がある。
引数は入力のテキストである (
str型)。戻り値は 2 要素のタプルのリストである。タプルの各要素の意味は以下の通りである。
- 抽出したデータの開始位置 (
int型)。 - 抽出したデータの長さ (
int型)。
- 抽出したデータの開始位置 (
def split(self, text):
return [(0, 1)]
サンプルとして、空白文字で文章を区切る実装がデフォルトで提供されている。 詳細は space_splitter モジュール のソースを参照すること。
"string_types": {
"split_by_space": {
"method": "dynamic",
"path": "libpython_bridge.so",
"function": "word_splitter",
"module": "space_splitter",
"class": "SpaceSplitter"
}
},
"string_rules": [
{ "key": "*", "type": "split_by_space", "sample_weight": "tf", "global_weight": "bin" }
]
num_feature インタフェース¶
クラスにインスタンスメソッド extract (2 引数) を定義する必要がある。
引数は入力の datum のキー名 (
str型) とその値 (double型) である。戻り値は 2 要素のタプルのリストである。タプルの各要素の意味は以下の通りである。
- 特徴次元のキー名 (
str型)。 - そのキー名に対応する値 (
double型)。
- 特徴次元のキー名 (
def extract(self, key, value):
return [(key, value)]
サンプルとして、入力された数値を N 倍に変換する実装がデフォルトで提供されている。 詳細は number_multiplier モジュール のソースを参照すること。
"num_types": {
"multiply_by_3": {
"method": "dynamic",
"path": "libpython_bridge.so",
"function": "num_feature",
"module": "number_multiplier",
"class": "NumberMultiplier",
"n": "3"
}
},
"num_rules": [
{ "key": "*", "type": "multiply_by_3" }
]
binary_feature インタフェース¶
クラスにインスタンスメソッド extract (2 引数) を定義する必要がある。
引数は入力の datum のキー名 (
str型) とその値 (bytes型) である。戻り値は 2 要素のタプルのリストである。タプルの各要素の意味は以下の通りである。
- 特徴次元のキー名 (
str型)。 - そのキー名に対応する値 (
double型)。
- 特徴次元のキー名 (
def extract(self, key, value):
return [(key, len(value))]
サンプルとして、入力されたバイナリデータを特徴として抽出する実装がデフォルトで提供されている。 詳細は binary_length モジュール のソースを参照すること。
"binary_types": {
"extract_length": {
"method": "dynamic",
"path": "libpython_bridge.so",
"function": "binary_feature",
"module": "binary_length",
"class": "BinaryLengthExtractor"
}
},
"binary_rules": [
{ "key": "*", "type": "extract_length" }
]